Tópicos Especiais em Algoritmos Ciência da Computação
Paradigmas de Resolução de Problemas
- Busca Completa
- Divisão e Conquista
- Algoritmos Gulosos
- Programação Dinâmica
- Problemas Clássicos
- Leituras Recomendadas
Várias soluções compartilham uma mesma linha de raciocínio, um mesmo paradigma de projeto. Veremos agora os principais paradigmas de projeto de algoritmos e como podemos utilizá-los para resolver problemas eficientemente.
Busca Completa
Como o nome indica, a busca completa é responsável por exaurir todo (ou quase todo) o espaço de busca do problema em busca de uma solução.
Uma solução baseada em Busca Completa nunca deveria estar errada, uma vez que todas as possibilidades de solução são checadas.
Para ilustrar o conceito, tome o seguinte problema (UVA 725): dado dois inteiros $A=abcde$ e $B=ghijk$ de $5$ dígitos cada de modo que todos os dígitos de $0$ a $9$ sejam utilizados coletivamente pelos dois e um inteiro $N$, encontrar (quando possível) todos os valores de par $(A,B)$ tal que :
\[\frac{abcde}{ghijk} = N\]Obviamente, o menor valor para $A$ e $B$ é $01234$, já o maior consiste em $98765$, assim, todos os possíveis valores de $A$ e $B$ estão no intervalo $[01234,98765]$, o que configura um espaço com tamanho $\approx10^5$. Como a divisão deve ser igual a $N$, podemos assumir que o espaço de busca é menor ainda, principalmente quando $N$ cresce. Dada essa discussão, o seguinte trecho de código é capaz de explorar todo o espaço de busca e resolver o problema:
// Gera todas as possibilitades no intervalo [01234,98765]
for (int fghij = 1234; fghij <= 98765 / N; fghij++) {
int abcde = fghij * N; // Calcula abcde de fghij
/***
* used é uma sequência de bits de modo que o dígito i foi
* utilizado se e somente se o i-ésimo bit desta sequência
* está ligado. Obviamente o bit 0 estará ligado sempre que fghij < 10000.
***/
int tmp, used = (fghij < 10000);
tmp = abcde;
/***
* Extrai os dígitos de tmp = abcde e marca os que foram usados
* na variável used
***/
while (tmp) {
used |= 1 << (tmp % 10);
tmp /= 10;
}
/***
* Extrai os dígitos de tmp = fghij e marca os que foram usados
* na variável used.
***/
tmp = fghij;
while (tmp) {
used |= 1 << (tmp % 10);
tmp /= 10;
}
/***
* Se todos os dígitos foram utilizados coletivamente, significa que
* o par (A,B) foi encontrado.
***/
if (used == (1<<10) - 1){
printf("%0.5d / %0.5d = %d\n", abcde, fghij, N);
}
}Considerando agora o seguinte problema (UVA 441): Dado um conjunto de $k$ ($6\leq k < 13$) inteiros em ordem crescente, imprimir todos os subconjuntos de tamanho $6$ em ordem lexicográfica. O número máximo de subconjuntos pode ser expresso como:
\[\binom{12}{6} = 924\]Ou seja, no máximo existe apenas $924$ possibilidades de acordo com as restrições do problema, o que é um espaço de busca bastante reduzido. Assim, para resolver o problema supracitado, basta utilizar uma estrutura com $6$ laços de repetição aninhados.
for (int i = 0; i < k; i++)
// Entrada: k inteiros em ordem crescente
scanf("%d", &v[i]);
for (int a = 0; a < k - 5; a++)
for (int b = a + 1; b < k - 4; b++)
for (int c = b + 1; c < k - 3; c++)
for (int d = c + 1; d < k - 2; d++)
for (int e = d + 1; e < k - 1; e++)
for (int f = e + 1; f < k; f++)
printf("%d %d %d %d %d %d\n",v[a],v[b],v[c],v[d],v[e],v[f]);Uma estratégia parecida pode ser adotada no problema (UVA 11565), que consiste em, dados três inteiros $A$, $B$ e $C$ ($1\leq A,B,C \leq 10^5$), encontrar valores distintos $x$,$y$ e $z$ que satisfaçam simultâneamente as três equações abaixo:
\[\begin{eqnarray} x + y + z & = & A\\ x * y * z & = & B\\ x^2 + y^2 + z^2 & = & C \end{eqnarray}\]No caso de haver múltiplas valorações que satisfaçam as equações simultêamente, a solução deverá escolher aquela com menor valor para $x$ possível.
De acordo com a última equação, é fácil ver que os valores de $x$, $y$ e $z$ obrigatoriamente devem estar no intervalo $[-100,100]$ de acordo com as restrições do tamanho de $A$, $B$ e $C$. Assim, ao todo temos $201 \cdot 201 \cdot 201 = 8.12 \cdot 10^6$ possibilidades, o que não é muito. Considerando esta observação, temos o seguinte código como solução.
bool sol = false;
int x, y, z;
for (x = -100; x <= 100; x++)
for (y = -100; y <= 100; y++)
for (z = -100; z <= 100; z++)
// x,y e z devem ser distintos
if (y != x && z != x && z != y &&
x + y + z == A && x * y * z == B &&
x * x + y * y + z * z == C) {
if (!sol)
printf("%d %d %d\n", x, y, z);
sol = true;
}Mais otimizações poderiam ser realizadas. Levando em consideração a equação $x * y * z = B$ e tomando o caso em que $x = y = z$, temos que $x *x * x < B$ e portanto, $x<\sqrt[3]{10^5}$. Logo, o intervalo considerado para $x$ poderia ser de $[-22,22]$, reduzindo ainda mais o espaço de busca.
Considere agora o problema UVA 11742, que consiste em: dado um número $N$ ($1\leq N \leq 8$) de pessoas que querem ver um filme e um número $M$ ($1\leq M \leq 20$) de restrições, calcular o total de possibilidades possíveis segundo as restrições. Uma restrição consiste em duas pessoas e o número máximo (ou mínimo) de assentos nos quais estas pessoas devem estar afastadas.
Gerar todas as permutações possíveis de pessoas leva tempo $O(N!)$ e checar se uma permutação está consistente com as restrições, leva tempo $O(M+N)$ com uma a implementação for cuidadosa, desta forma, o custo total do algoritmo seria $O((M+N)\cdot N!)$, o que é factível pelas dimensões do problema. Felizmente, para gerar todas as permutações, é possível utilizar a biblioteca <algorithm> juntamente com o método next_permutation, que dada uma permutação, gera a próxima.
O problema em questão, poderia ser resolvido segundo o esboço abaixo.
int count = 0;
vector<int> perm;
// Perm = {0,1,...,n-1}
for(int i=0;i<n;i++){
perm.push_back(i);
}
// Gera todas as permutações
do{
// Verifica se a permutação é consistente com as restrições
if(check(perm,restricoes)){
// Se for o caso, incremente o número de possibilidades
count++;
}
}while(next_permutation(perm.begin(),perm.end()));
cout << count << endl;No problema UVa 12455, dado um conjunto de inteiros $S$, ($1\leq \lvert S\lvert \leq 20$) e um inteiro $X$, deseja-se saber se existe algum subconjunto de $S$ cuja soma é $X$. Tal problema é conhecido como Subset Sum e pode ser resolvido via Programação Dinâmica, entretanto, devido às restrições do tamanho de $S$, ele é passível de ser resolvido por busca completa, gerando no máximo $O(2^n)$ subconjuntos. Traduzindo para o tamanho da entrada, são feitas na ordem de $2^{20} \approx 10^6$ operações.
Utilizando operações bit-a-bit, é possível gerar todos os subonjuntos de um conjunto $S$ de uma forma iterativa, basta lembrar que, utilizando $n$ bits, é possível representar $2^n$ valores. Desta forma, todos os inteiros no intervalo $[0,2^n]$ representariam cada um subconjunto de $n$ elementos de forma que, se o $i$-ésimo bit do inteiro está ligado, significa que o $i$-ésimo elemento do conjunto original pertence ao subconjunto. Caso o $i$-ésimo bit estivesse desligado, o oposto valeria, isto é, que o $i$-ésimo elemento de $S$ não pertence ao subconjunto associado ao inteiro. Isso dá margem para a seguinte solução.
// Gera todos os subconjuntos possíveis
bool res = false;
for (i = 0; i < (1 << n); i++) {
int sum = 0;
// Para cada elemento do conjunto, verifique se ele pertence a S
for (int j = 0; j < n; j++){
// Caso o j-ésimo bit esteja ligado, o j-ésimo elemento de S
// Pertence ao conjunto
if (i & (1 << j)){
// Adiciona S[j] ao acumulador
sum += S[j];
}
}
// Caso o subconjunto tenha soma X, a resposta é sim
if (sum == X){
ans = true;
}
}Backtracking
Um método bem conhecido que utiliza da busca completa é o backtracking. Durante a busca no backtraking, é possível realizar algumas “podas” e deixar de explorar algumas regiões do espaço de busca, desde que demonstradas que elas não contribuam para a solução final.
Vamos pegar como exemplo o problema clássico das 8 rainhas (UVA 750). Neste problema o objetivo é posicionar $8$ rainhas em um tabuleiro de xadrez, que possui dimensões $8\times 8$ sem que uma rainha esteja em posição de atacar a outra. A figura abaixo ilustra um exemplo de solução deste problema.

O número possível de configurações das $8$-rainhas é de $\binom{64}{8} = 4426165368 \approx 4\cdot 10^{10}$, o que representa um imenso espaço de busca.
Uma solução do jogo não pode admitir duas rainhas na mesma coluna, pois se fosse o caso, elas estariam em posição de ataque uma com a outra. Com esta observação, o espaço de busca é reduzido para $8^8 = 16777216 \approx 10^ 8$.
Utilizando o mesmo argumento acima, mas para as diagonais e linhas, o espaço de busca é reduzido substancialmente, ou seja, a posição de uma rainha é válida somente se ela não encontra-se na mesma coluna, diagonal ou linha de outra rainha.
A solução pode ser colocada como o seguinte código.
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <iomanip>
using namespace std;
// Posição da rainha em cada coluna
int row[8];
// Posição da primeira rainha
int a, b;
// Contador da linha
int lineCounter;
// Tenta inserir a c-ésima rainha na linha r da c-ésima coluna
bool place(int r, int c) {
for (int prev = 0; prev < c; prev++){
// Para cada uma das c-1 rainhas anteriores, checa se a nova rainha
// Está na mesma linha ou diagonal
if (row[prev] == r || (abs(row[prev] - r) == abs(prev - c))){
// Se sim, não é possível inserir a c-ésima rainha na posição
// r da c-ésima coluna
return false;
}
}
return true;
}
void backtrack(int c) {
/***
* Se o número de rainhas inseridas é 8 e existe uma rainha na posição
* (a,b), então é uma solução válida
***/
if (c == 8 && row[b] == a) {
++lineCounter;
cout << setw(2) << lineCounter << " " << row[0]+1;
for (int j = 1; j < 8; j++){
cout << " " << row[j] + 1;
}
cout << endl;
return;
}
// Para cada posição possível da coluna, tenta inserir a rainha
for (int r = 0; r < 8; r++){
// Tenta inserir a c-ésima rainha na posição r da coluna
if (place(r, c)) {
// Se for possível, insere a rainha e tenta inserir a próxima
// recursivamente
row[c] = r;
backtrack(c + 1);
}
}
}
int main() {
int tc;
cin >> tc;
while(tc--){
// Posição da primeira rainha
cin >> a >> b;
// Conversão para base 0
a--; b--;
// Zera o vetor
memset(row, 0, sizeof row);
lineCounter = 0;
cout << "SOLN COLUMN\n";
cout << " # 1 2 3 4 5 6 7 8\n\n";
// Generate solutions
backtrack(0);
if (tc)
cout << endl;
}
return 0;
}Dicas para Soluções Baseadas em Busca Completa
O principal problema de uma solução baseada em busca completa é justamente o tamanho do espaço de busca. No entanto, existem algumas dicas que podem ajudar no projeto de uma solução deste tipo.
- (Geradores vs Filtros) Programas podem ser baseados em gerar todas as soluções e selecionar aquelas válidas, como no caso do exemplo das 8-rainhas, ou gerar uma solução válida incrementalmente, partindo de subsoluções, ao mesmo tempo que poda soluções inválidas. A primeira situação é mais simples de construir, mas a segunda geralmente tem uma eficiência maior.
- (Poda de soluções inválidas ou piores) Pode soluções inválidas o mais cedo possível, isso acarretará em um espaço de busca menor e consequentemente, menos processamento será utilizado. Outra estratégia é, se dada uma subsolução, o possível valor da solução formada a partir desta for pior que o valor de uma solução já encontrada, a poda pode ser efetuada sem problemas.
- (Explore a Simetria) algumas soluções podem ser obtidas de outras soluções considerando uma rotação ou um espelhamento, dispensando efetuar o processamento para encontrá-las. Sempre que necessário, explore essa propriedade.
- (Pré-processamento) Dependendo do problema, é vantajoso perder um tempo construindo alguma estrutura de dados que agilize algum tipo de consulta, isto é conhecido como pré-processamento.
- (Otimize seu código) Procure otimizar sempre que possível, métodos de leitura, acesso a memória, uso da memória cache. Um bom entendimento da arquitetura de computador pode ajudar a agilizar uma solução baseada em busca completa. Exemplos:
- Acessar matrizes linha por linha é mais eficiente do que coluna por coluna;
- Utilizar vetores de bits é mais eficiente do que utilizar um vetor de booleanos ou de inteiros. Menos acessos à memória são necessários.
- Utilize estruturas fixas com tamanho suficiente para a maior entrada do problema. Isto pode ser preferível do que utilizar estruturas dinâmicas como
<vector>se o objetivo é otimizar o máximo de tempo possível. - Com base no exemplo anterior, declare o máximo dessas variáveis em escopo global (não use isso em qualquer coisa que não seja programação competitiva).
- Utilizar vetores para
charnormalmente é mais eficiente do que usar o tipostringdo C++.
- (Estruturas de Dados) Utilize melhores estruturas de dados e algoritmos. Às vezes a busca completa pode não ser a melhor solução.
Divisão e Conquista
Algoritmos Gulosos
Um algoritmo é dito guloso se ele faz uma escolha local ótima a cada passo esperando chegar na solução ótima global. Em alguns casos, os algoritmos gulosos funcionam bem: a solução é curta e eficiente. Em muitos outros casos, a solução gulosa não funciona.
Para um algoritmo guloso funcionar, ele deve:
- Possui subestrutura ótima:
- A solução ótima do problema pode ser decomposta em soluções ótimas de subproblemas.
- Ele tem que ter a propriedade gulosa:
- Se ao realizar uma escolha gulosa e proceder a resolver o problema que restou, chegamos na solução ótima, então existe a propriedade gulosa.
Vamos tomar alguns exemplos para ilustrar esse problema.
Problema do Troco
Seja uma quantia $V$ e uma lista de $n$ moedas, cada moeda possui um valor $value[i]$ em que $i\in [0,n-1]$.
A estratégia gulosa é: utilize a moeda com maior valor possível que é menor do que a quantia $V$ e continue com o subproblema $V-x$ em que $x$ é o valor da moeda utilizada.
Por exemplo, se $value={25,10,5,1}$ e $V=42$, então a estratégia faria:
- $V = 42$: utilize uma moeda de $25$, resta $17$.
- $V=17$: utilize uma moeda de $10$, resta $7$.
- $V=7$: utilize uma moeda de $5$, resta $2$.
- $V=2$: utilize uma moeda de $1$, resta $1$.
- $V=1$: utilize uma moeda de $1$, fim.
Essa estratégia, para este sistema de moedas, leva a uma solução ótima, com um total de $5$ moedas.
Analisando melhor o problema, temos que:
- Ele tem subestrutura ótima:
- Para resolver o problema com $V=42$ utilizamos a solução de quando $V=17$, uma vez que as moedas $10+5+1+1$ foram utilizadas.
- Ele tem a propriedade gulosa: para cada quantidade $V$, podemos escolher a maior moeda que é menor ou igual a $V$ que nos levará a solução ótima global.
A estratégia gulosa nos fornece um sistema muito simples, mas ela só funciona no caso de um sistema canônico de moedas, que é o caso da maioria dos sistemas financeiros. Caso as moedas disponíveis fossem $value = {4,3,1}$ e o valor a ser pago fosse $V=6$, a estratégia gulosa nos daria $3$ moedas enquanto a solução ótima consiste de duas moedas de $3$.
Para resolver o problema geral do troco, em que o sistema de moedas não necessáriamente é canônico, pode-se utilizar a abordagem de Programação Dinâmica.
UVa 410 - Station Balance
Tome o problema UVa 410. Existem $1\leq C \leq 5$ câmaras que podem armazenar $0$,$1$ ou $2$ espécimes, $1 \leq S \leq 2C$ espécimes e uma lista $M$ da massa de cada uma das $S$ espécimes. O problema consiste em determinar qual câmara deve armazenar cada espécime para minimizar o desequilíbrio.
Este é um problema conhecido como balanceamento de carga, muito utilizado no contexto de Máquinas Virtuais e Computação em Nuvem. Basicamente, seja: $A$ a média da massa considerando as $C$ câmaras:
\[A = \sum_{j=1}^{S} \frac{M_j}{C}\]O objetivo é minimizar
\[\sum_{i=1}^{C} |X_i -A|\]Em que $X_i$ é a massa total presente na $i$-ésima câmara.
Isto é, minimiza a soma das diferenças da massa total em cada câmara em relação a média $A$.
A estratégia gulosa que resolve esse problema é a seguinte:
- Se $S<2C$, adicione $2C-S$ espécimes com massa $0$.
- Ordene as espécimes pela massa.
- Para cada câmara $i$: pareie as espécimes de massa $M_i$ e $M_{2C-i+1}$ na câmara.
Uma dica que funciona neste caso, e em muitos outros, é que em alguns casos, ordenar a entrada pode ajudar.
UVa 10382
Tome agora o problema UVa 10382. Suponha uma faixa retangular de grama com dimensões de comprimento e largura $l\times w$ e uma quantidade de $n$ irrigadores. Cada irrigador possui uma abrangência circular com raio $R$ e está posicionado no centro da faixa de grama e com o centro posicionado a uma distância horizontal do início da faixa, conforme figura abaixo:
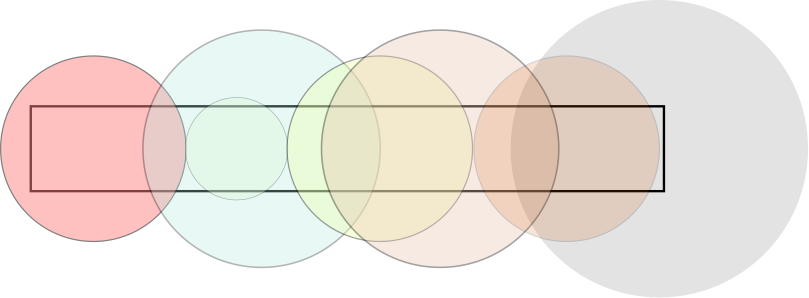
Como o número de irrigadores é no máximo $10000$, uma solução via busca completa é inviável, levaria $2^{10000}$ possibilidades, uma vez que esse número representa a quantidade de subconjuntos de irrigadores possíveis.
Fazendo uma análise trigonométrica, é possível ver que, cada irrigador cobre no máximo uma distância horizontal $d_x$ do seu centro, conforme figura abaixo:
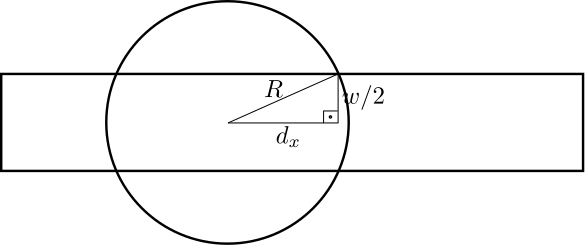
Como temos um triângulo retângulo, o valor de $d_x = \sqrt{(R^2 - \frac{W}{2}^2 )}$. Logo, cada círculo com centro em $(x,y)$, cobre todo o intervalo da faixa $[x-dx,x+dx]$.
Reduzimos este problema para o problema de interseção de intervalos que possui uma solução gulosa!
- Ordene todos os círculos em ordem crescente pela extremidade da esquerda $x-dx$. Em caso de empate, dê preferência para o maior valor de $x+dx$ (extremidade da direita).
- Insira o primeiro círculo na solução. Caso ainda exista uma porção não coberta à esquerda do primeiro círculo, a resposta já é não.
- Enquanto houver círculos a serem analisados ou enquanto a faixa não tiver sido coberta.
- Escolha o círculo com maior $x+dx$ e que tenha interseção com o último cículo inserido na solução e coloque o círculo escolhido na solução..
- Cheque a solução e verifique se ela tem “buracos”. Em caso negativo, você conseguiu encontrar a menor quantidade de irrigadores que resolve o problema, que corresponde ao número de círculos na solução.
UVa 11292
No problema UVa 11292 são dados $n$ cabeças de dragão e $m$ cavaleiros. Cada cabeça de dragão tem um diâmetro $D$ e cada cavaleiro tem uma altura $H$. O cavaleiro pode cortar a cabeça do dragão somente se a sua altura $H\geq D$.
Dado uma lista de diâmetros de cabeça e outra de alturas de cavaleiros, o problema consiste em determinar
- Se é possível cortar todas as cabeças de dragão
- Em caso afirmativo, qual o total mínimo da soma das alturas dos cavaleiros que compõem uma solução.
Neste problema, mas uma vez ordenar faz sentido. Ordena-se a lista de alturas e diâmetros de cabeça e utiliza-se a seguinte inspeção linear:
/***
* (...)
* Ordene as listas primeiramente
* (...)
***/
gold = d = k = 0;
// Enquanto não se chega no fim de uma das listas
while(d<n && k<m){
// Enquanto o diâmetro da cabeça é maior que a altura do cavaleiro
while(dragon[d] > knight[k] && k<m){
// Passe para o próximo cavaleiro
k++;
}
if(k==m)
break;
gold+= knight[k];
d++;
k++;
}
if(d==n)
cout << gold << endl;
else
cout << "Loowater is doomed!" << endl;Dicas para Algoritmos Gulosos
- Provar a correção da solução gulosa leva tempo.
- Se o tamanho da entrada for suficientemente pequeno para acomodar uma solução de Programação Dinâmica ou Busca Completa, utilize ela em vez da solução gulosa, uma vez que esta não é certa de funcionar em qualquer problema.
- Ordenar a entrada pode ajudar a pensar na escolha gulosa.
- Algoritmos gulosos geralmente são eficientes em contrapartida aos elaborados usando outras abordagens.
Programação Dinâmica
Para ilustrar o conceito de Programação Dinâmica, utilizaremos um exemplo do problema UVa 11450.
Este problema é sobre compras de peças de vestuário para ir a um casamento. Existe $C$ ($1\leq C \leq 20$) tipos de peças de roupa diferentes e $M$ ($1\leq M \leq 200$) o montante disponível. Para cada um dos $C$ tipos de peça, existe um número $K$ ($1\leq K \leq 20$) de peças daquele tipo, cada um com uma descrição de preço. O objetivo é gastar o máximo possível, comprando exatamente uma peça de cada tipo, sem exceder uma quantia $M$ ($1\leq M \leq 200$)
A solução deverá indicar qual o valor máximo gasto, ou a impossibilidade de gastar um valor menor ou igual a $M$.
Para exemplificar o problema, tome o seguinte cenário, o montante disponível é $M=20$, e existem três tipos de peça:
- Três camisas com custos $(6,4,8)$.
- Duas gravatas com custos $(5,10)$.
- Três sapatos com custos $(1,5,3,5)$.
Uma solução para este problema é pegar uma camisa de custo $8$, uma gravata e custo $10$ e um sapato de custo $1$, totalizando $19$. Outra solução seria obter uma camisa de custo $6$, uma gravata de custo $10$ e um sapato de custo $3$. Não existe solução que gaste $20$.
Supondo o mesmo cenário, mas com $M=9$, mesmo se pegássemos os items mais baratos de cada tipo, não conseguiríamos ficar abaixo do montante disponível. Neste caso, o problema não possui uma solução.
Abordagem 1: Algoritmo Guloso (WA)
Podemos pensar em um algoritmo guloso que sempre pega o item mais caro de cada tipo que não excede o montante disponível. No entanto, a solução nem sempre é correta.
Tome o exemplo anterior, mas com $M=12$. Com uma abordagem gulosa, inicialmente, pegaríamos uma camisa de custo $8$, reduzindo o montante para $M=4$ e com esta quantia, não conseguimos comprar nenhuma gravata. O algoritmo guloso então reportaria que não existe solução, quanto na verdade, uma solução ótima nesse cenário envolve uma camisa com custo $4$, uma gravata de custo $5$ e um sapato de custo $3$ ($4+5+3 = 12$).
Abordagem 2: Divisão e Conquista (WA)
Este problema não pode ser resolvido via o paradigma de divisão e conquista pelo motivo de que os subproblemas não são independentes um do outro.
Abordagem 3: Busca Completa (TLE)
A abordagem de busca completa pode resolver esse problema, mas devido ao tamanho da entrada, ela tomará muito tempo. A estratégia é, escolha o $i$-ésimo modelo do $j$-ésimo tipo de peça, subtraia o montante atual pelo preço do $i$-ésimo modelo e proceda recursivamente para o $j+1$-ésimo tipo de peça. De todas as combinações válidas, escolhemos aquela que maximiza a quantia gasta e que não excede o montante inicial.
O código abaixo ilustra um esboço da solução.
#include <bits/stdc++.h>
using namespace std;
/**
* @brief Realiza o backtracking para encontrar a melhor solução. Obviamente
* a chamada inicial deve ser backtracking(M,0).
*
* @param current_m montante atual
* @param idx: indíce do tipo da peça de roupa considerada
* @return int o máximo valor que pode ser gasto sem exceder a quantia M ou
* o menor inteiro possível caso não haja solução.
*/
int backtracking(int current_m,int idx){
if(current_m < 0){
// Caso excedamos o montante M, retorna-se um número negativo grande
return numeric_limits<int>::min();
}
if(idx==C && current_m >=0){
// Pegamos C elementos de diferentes tipos
return M - current_m;
}
/***
* Inicializamos a resposta como número negativo, representando a
* impossibilidade da solução.
***/
int ans = numeric_limits<int>::min();
for(int i=0;i<qtd[idx];i++){
/***
* Para cada uma das peças do tipo idx, resolva o problema
* recursivamente considerando que a i-ésima peça do tipo IDX foi
* escolhida, subtraindo sempre o preço da peça do tipo idx do montante
* atual
***/
ans = max(ans,backtracking(current_m-preco[idx][i],idx+1));
}
return ans;
}Como uma entrada pode ter no máximo $C = 20$ tipos de peça e cada tipo de peça pode possuir $K=20$ modelos, temos que a busca completa leva $20^{20}$, operações, o que é demais.
Abordagem 4: Programação Dinâmica Top-Down (AC)
Podemos perceber que o problema tem duas propriedades interessantes.
- Subestrutura ótima: a solução para o subproblema é parte da solução do problema maior. Isto é, se o $i$-ésimo elemento do $k$-ésimo tipo tipo de peça está na solução, a solução do subproblema sem a peça escolhida tem que ser ótima.
- O problema tem sobreposição de subproblemas. O espaço de busca $20^{20}$ possui muitos subproblemas que se sobrepõem.
O item 2. é chave para as soluções baseadas em DP. Como existe sobreposição de subproblemas, podemos trocar espaço por tempo. Sempre que um subproblema é resolvido, armazenamos a sua solução e, no caso de sua recorrência, o valor já computado é utilizado.
Podemos utilizar a solução baseada em busca completa discutida anteriormente e utilizar uma técnica de memoization para guardar as soluções dos subproblemas. Sempre que nos deparamos com subproblemas, primeiramente verificamos se eles já foram resolvidos: em caso afirmativo, utilizamos a solução já computada, em caso negativo, computamos a solução e armazenamos a resposta em uma ED.
Isso dá origem ao seguinte algoritmo:
#include <bits/stdc++.h>
using namespace std;
int M,C;
vector<vector<int>> price;
vector<vector<int>> memo;
vector<int> quantity;
int shop(int current_m, int idx){
if(current_m<0){
/*** Caso base, retornamos um inteiro negativo grande caso o
* montante atual seja negativo
***/
return numeric_limits<int>::min();
}
if(idx==C){
/*** Caso contrário, chegamos em uma solução, não necessariamente
* ótima, e o valor total gasto é M - current_m */
return M-current_m;
}
// Verificamos se o problema já foi resolvido
if(memo[current_m][idx]!=-1){
return memo[current_m][idx];
}
int ans = numeric_limits<int>::min();
for(int i=0;i<quantity[idx];i++){
ans = max(ans,shop(current_m-price[idx][i],idx+1));
}
memo[current_m][idx] = ans;
return ans;
}
int main(){
int t;
cin >> t;
while(t--){
cin >> M >> C;
quantity.assign(C,0);
price.clear();
price.resize(C);
memo.assign(M+1,vector<int>(21,-1));
for(int i=0;i<C;i++){
cin >> quantity[i];
price[i].resize(quantity[i]);
for(int j=0;j<quantity[i];j++){
cin >> price[i][j];
}
}
int ans = shop(M,0);
if(ans<0)
cout << "no solution" << endl;
else
cout << ans << endl;
}
}Como estamos referenciado uma única célula, podemos deixar o código mais enxuto ao utilizar uma referência para a célula.
int shop(int current_m, int idx){
if(current_m<0){
/*** Caso base, retornamos um inteiro negativo grande caso o
* montante atual seja negativo
***/
return numeric_limits<int>::min();
}
if(idx==C){
/*** Caso contrário, chegamos em uma solução, não necessariamente
* ótima, e o valor total gasto é M - current_m */
return M-current_m;
}
// Verificamos se o problema já foi resolvido
int& ans = memo[current_m][idx];
if(ans !=-1) return ans;
for(int i=0;i<quantity[idx];i++){
ans = max(ans,shop(current_m-price[idx][i],idx+1));
}
return ans;
}Abordagem 5: Programação Dinâmica Bottom-up (AC)
É possível implementar uma solução de Programação Dinâmica interativa, sem o uso de recursão. Chamamos essa abordagem de bottom-up. A estratégia dela é construir a solução de problemas do menor para o maior tamanho.
Vamos modelar o problema da seguinte forma: a solução de $S(i,m)$ nos diz se é possível ter o montante $m$ restante após comprar uma peça de cada um dos $i+1$ primeiros tipos. Claramente, $S(0,m)$ é verdadeiro sempre que $M-x\geq 0$, em que $x$ é o preço dos items de tipo $0$.
Suponha agora que tenhamos $S(i,m)$ computado para todo $0\leq i < C$ e $0\leq m \leq M$. Caso seja possível chegar no montante final $m$ após utilizar os $i$ primeiros tipos, tentamos incluir as peças do $i+1$-ésimo primeiro tipo na solução. Para cada valor das peças de tipo $i+1$, verificamos se o montante $m$ de $S(i,m)$ que sobrou é suficiente para incluir a peça, se for possível, então $S(i+1,m-x)$ tem que ser verdadeiro, em que $x$ é o valor da peça.
Resumindo o discutido em uma única relação de recorrência, temos:
Isso gera a seguinte solução.
#include <bits/stdc++.h>
using namespace std;
int M,C;
vector<vector<int>> price;
vector<int> quantity;
void solve(){
vector<vector<bool>> dp;
dp.assign(C+1,vector<bool>(M+1,false));
// Caso base
for(int i=0;i<quantity[0];i++){
/***
* Considerando apenas o primeiro tipo, verificamos cada item
* deste tipo e, caso o preço dele seja menor que o montante inicial
* indicamos que conseguimos pagar a quantia.
***/
if(M - price[0][i] >= 0){
dp[0][M-price[0][i]]=true;
}
}
// Caso geral, para cada tipo de item
for(int k=1;k<C;k++){
// Para cada quantia, de 0 a M
for(int m = 0 ;m<=M;m++){
/***
* Se for possível pagar o valor m utilizando os k-1 primeiros
* itens, testamos os itens do k-ésimo tipo
***/
if(dp[k-1][m]){
for(int i=0;i<quantity[k];i++){
/*** Se é possível incluir o i-ésimo tipo na solução
* respeitando o teto m, marcamos como verdadeiro ***/
if(m - price[k][i] >= 0){
dp[k][m-price[k][i]]=true;
}
}
}
}
}
/*** Verificamos qual a maior quantia que é possível pagar com os C
* items ***/
int ans;
for(ans = 0; ans<=M && !dp[C-1][ans];ans++);
if(ans == M+1)
cout << "no solution" << endl;
else
cout << M - ans << endl;
}
int main(){
int t;
cin >> t;
while(t--){
cin >> M >> C;
quantity.assign(C,0);
price.clear();
price.resize(C);
for(int i=0;i<C;i++){
cin >> quantity[i];
price[i].resize(quantity[i]);
for(int j=0;j<quantity[i];j++){
cin >> price[i][j];
}
}
solve();
}
}É fácil ver que, para a computação da $i$-ésima linha desta tabela, só precisamos olhar para a linha anterior. Então poderíamos economizar espaço e utilizar uma tabela com duas linhas, uma para a solução do $i-1$-ésimo item e uma para a solução considerando o $i$-ésimo item.
Comparação entre as abordagens Top-Down e Bottom-Up
Ambas as abordagens são interessantes para resolução de problemas envolvendo programação dinâmica, cada uma com suas vantagens e desvantagents.
Top-Down:
- Vantagens
- Pode ser derivada de uma solução baseada em busca completa.
- Computa os subproblemas apenas quando necessário.
- Desvantagens
- Mais lenta se subproblemas são revisitados frequentemente, por conta da chamada recursiva.
- Se existem $M$ possíveis estados, é necessário de uma tabela com dimensão $O(M)$.
Bottom-up:
- Vantagens
- Mais rápida se subproblemas são revisitados frequentemente.
- Mais econômica em espaço se utilizar o truque de excluir uma dimensão.
- Desvantagens
- Mais difícil para programadores que possuem mais afinidade com recursão.
- Todos os subproblemas devem ser resolvidos para construir a solução de problemas maiores.
Problemas Clássicos
A seguir serão ilustrados vários problemas clássicos da Computação que envolvem soluções baseadas em Programação Dinâmica.
2D Range Sum
Dada uma matriz $M_{n\times m}$ contendo números inteiros (positivos e negativos), o objetivo é achar o retângulo que maximize a soma dos inteiros contidos nele e dizer qual a soma.
Solução força-bruta
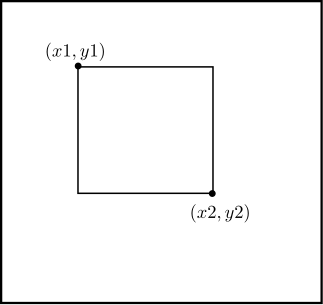
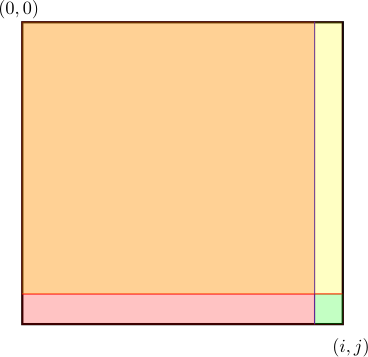
A solução força-bruta simplesmente computa, de maneira ingênua, a soma de todos os possíveis retângulos. Um retângulo é definido por um par de coordenadas $(x_1,y_1)$ e $(x_2,y_2)$, em que o primeiro representa o canto superior esquerdo e o último o canto inferior direito, conforme figura abaixo.
Essa solução força-bruta pode ser representada de acordo com o seguinte esboço.
/**
* @brief Retorna a soma do retângulo definido pelas coordenadas
* (i,j) e (ii,jj).
*
* @param i linha do canto superior esquerdo.
* @param j coluna do canto superior esquerdo
* @param ii linha do canto inferior direito
* @param jj coluna do canto inferior direito
*/
int sum(int i,int j,int ii,int jj){
int s = 0;
for(int k=i;k<=ii;k++){
for(int l=j;l<=jj;l++){
s += M[k][l];
}
}
return s;
}
/**
* @brief Acha a maior soma dentre todos os possíveis retângulos.
*
* @return int a maior soma.
*/
int find_max_sum(){
int max_sum = 0;
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
for(int ii=i;ii<n;ii++){
for(int jj=j;jj<m;jj++){
max_sum = max(max_sum,sum(i,j,ii,jj));
}
}
}
}
return max_sum;
}O algoritmo apresentado é ineficiente, uma vez que existem $\Theta(n^2m^2)$ possíveis retângulos, o que nos levaria a um algoritmo com complexidade total de $\Theta(n^3m^3)$.
Solução Programação Dinâmica
Podemos resolver esse problema em tempo $\Theta(n^2m^2)$ desde que seja possível realizar a soma de um retângulo $(x_1,y_1)$ $(x_2,y_2)$ em tempo constante. Para isso utilizaremos uma técnicas de programação dinâmica.
Suponha que uma matriz $S_{n\times m}$ foi computada e que $S[i,j]$ contém a soma do retângulo $(0,0)$ $(i,j)$. Como computar a soma do retângulo $(x_1,y_1)$ $(x_2,y_2)$ a partir disso?
Observando a figura abaixo, temos que a soma contida no retângulo $(x_1,y_1)(x_2,y_2)$ é simplesmente a soma do retângulo $(0,0)(x_2,y_2)$ (cores rosa, roxo, dourado e marrom) menos a soma do retângulo $(0,0)(x_2,y_1-1)$ (cores marrom e dourado), menos a soma do retângulo $(0,0)(x_1-1,y_2)$ (cores marrom e roxo), mais a soma do retângulo $(0,0)(x_1-1,y_1-1)$ (cor marrom). Temos que adicionar a soma do retângulo marrom, pois ele foi contabilizado duas vezes nos retângulos marrom/dourado e marrom/roxo.
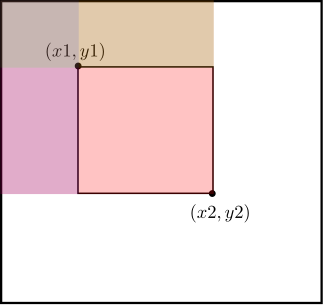
Traduzindo isso para termos de $S$, temos que a soma do retângulo $(x_1,y_1)(x_2,y_2)$ é simplesmente $S[y_2][x_2] -S[y_1-1][x_2] - S[y2][x_1-1] + S[y_1-1][x_1-1]$. Em código isso é ilustrado abaixo.
/**
* @brief Retorna a soma do retângulo definido pelas coordenadas
* (i,j) e (ii,jj).
*
* @param i linha do canto superior esquerdo.
* @param j coluna do canto superior esquerdo
* @param ii linha do canto inferior direito
* @param jj coluna do canto inferior direito
*/
int sum(int i,int j,int ii,int jj){
int a = S[ii][jj];
int b = S[i-1][jj];
int c = S[ii][j-1];
int d = S[i-1][j-1];
return a-b-c+d;
}Dado que $S$ está computado, a soma de qualquer retângulo pode ser obtida com $3$ operações aritméticas, portanto leva tempo $\Theta(1)$.
A pergunta que fica é: como computar $S$ em tempo eficiente? Utilizamos uma técnica similar. O retângulo $(0,0)(i,j)$ é simplesmente a soma do retângulo $(0,0)(i-1,j)$ mais a soma do retângulo $(0,0)(i,j-1)$ menos a soma do retângulo (0,0)(i-1,j-1) mais o valor contido na célula $M[i][j]$. Isto é exemplificado pela figura abaixo, o que fazemos é somar o retângulos vermelho e dourado, o retângulos dourado e amarelo, o retângulo verde e retiramos o retângulo dourado, pois foi contabilizado duas vezes.
Essa discussão é traduzida na seguinte relação de recorrência:
\[S(i,j) = \left\{ \begin{array}{l} M[0][0],\quad i=0 \land j=0\\ S(i-1,0) + M[i][0], \quad i>0 \land j = 0\\ S(0,j-1) + M[0][j],\quad i=0 \land j>0\\ S(i-1,j) + S(i,j-1) - S(i-1,j-1) + M[i][j],\quad i>0 \land j>0\\ \end{array} \right.\]O que gera o código abaixo.
/**
* @brief Computa a matriz S em tempo quadrático.
*
*/
void pre_process(){
S[0][0] = M[0][0];
for(int i=1;i<n;i++) S[i][0] = S[i-1][0] + M[i][0];
for(int j=1;j<m;j++) S[0][j] = S[0][j-1] + M[0][j];
for(int i=1;i<n;i++){
for(j=1;j<m;i++){
S[i][j] = S[i-1][j] + S[i][j-1] - S[i-1][j-1]+M[i][j];
}
}
}A partir do pré-processamento de $S$, que leva tempo $\Theta(nm)$ é possível calcular a soma de qualquer retângulo em tempo constante. Isso possibilitar a maior soma dentre todos os retângulos em tempo $\Theta(n^2m^2)$.
Longest Increasing Sequence (LIS)
Seja $V = (v_0,v_1,v_2,\ldots,v_{n-1})$ uma sequência de $n$ valores. Uma sequência $S$ é uma subsequência de $V$ se $S = (v_{i_0},v_{i_1},\ldots,v_{i_{k-1}})$ com $0\leq i_{0} < i_{1} < \ldots < i_{k-1} < n$. Em outras palavras, $S$ é uma subsequência de $V$ se pode ser formada por elementos de $V$, desde que lidos da esquerda para direita, e não necessariamente consecutivos. Por exemplo, se $V=(-7,10,9,2,3,8,8,1)$, uma subsequência de $V$ pode ser $S=(-7,9,2,3,1)$.
No problema da maior subsequência crescente (Longest Increasing Sequence ou LIS), o interesse é obter uma subsequência de $V$ que seja:
- Maior possível;
- Seus elementos sejam crescentes.
No caso do exemplo anterior, a maior subsequência crescente de $V=(-7,10,9,2,3,8,8,1)$ é $S=(-7,2,3,8)$, que possui comprimento $4$.
Obviamente a abordagem gulosa, de pegar o próximo elemento que é maior que o último escolhido não vai funcionar neste caso, pois se inserimos o $-7$ na solução, a abordagem gulosa incluiria o $10$ como próximo elemento, o que impossibilitaria a inserção de qualquer outro número.
Suponha que tenhamos calculado em $L(k)$ $(0\leq k < i)$ o tamanho da maior subsequência crescente de $V = (v_0,\ldots,v_k)$ e que termina obrigatoriamente com o item $v_k$, como computar $L(i)$?
Se $L(i)$ tem que terminar obrigatoriamente com $v_i$ temos que chegar quais das subsequências anteriores possibilitam a inserção de $v_i$ como último elemento (a subsequência deve ser crescente) e maximizam o tamanho.
Desta forma, podemos definir $L(i)$ como:
\[L(i) = \left\{ \begin{array}{l} 1,\quad i = 0\\ x+1,\quad \text{ em que } x = \max_{0\leq k <i}\{|L(k)|\;|\; v_k < v_i\},\quad i>0 \end{array} \right.\]Esta relação de recorrência pode ser traduzida no seguinte código.
/**
* @brief Computa o tamanho da maior subsequência
* crescente de v
*
* @param v entrada
* @return int retorna o tamanho da maior
* subsequência crescente de v
*/
int lis(vector<int>& v){
// Inicializamos uma tabela com 1s
vector<int> dp(v.size(),1);
// Tamanho da maior subsequência crescente
int max_l = dp[0]; // caso base, dp[0] = 1
for(size_t i =1;i<v.size();i++){
for(size_t j=0;j<i;j++){
/***
* Testamos se conseguimos estender a maior
* subsequência crescente
* que tem v[j] como último elemento
***/
if(v[i]>v[j])
/***
* Em caso positivo, dp[i] guarda a
* maior extensão possível
***/
dp[i] = max(dp[i],dp[j]+1);
}
max_l = max(max_l,dp[i]);
}
return max_l;
}Boolean Knapsack (Mochila Booleana)
Outro problema clássico é o Problema da Mochila 0-1. Neste problema, existe uma coleção de $n$ itens, cada um contendo um peso $w[i]$ e um valor $v[i]$. O objetivo é escolher itens de modo a maximizar o valor sem exceder uma capacidade de peso $W$. No caso deste problema, existe uma única instância de cada item.
Por exemplo se $v=(100,70,50,10)$, $w = (10,4,6,12)$ e $W = 12$, uma solução que maximiza o valor dos itens, sem exceder a capacidade $W$, é pegar os itens de peso $4$ e $6$ obtendo o valor $120$.
A solução de programação dinâmica consiste em computar a seguinte relação de recorrência:
\[T(i,j) = \left\{ \begin{array}{l} 0,\quad j<w[0]\\ v[0],\quad i=0\land j\geq w[0]\\ \max(a,b),\quad i>0 \quad \text{ em que} \\ \qquad a = T(i-1,j)\\ \qquad b = T(i-1,j-w[i]) + v[i],\quad \text{ se $j\geq w[i]$}, \text{ ou $b=0$, caso contrário}.\\ \end{array} \right.\]Esta equação nos diz qual o maior valor que é possível obter considerando apenas os itens de valor $v_0,\ldots,v_i$ com pesos $w_{0},\ldots,w_{i}$ e que não excedam a capacidade $j$. Podemos ver que o caso base desta equação de recorrência é $0$, quando $i=0\lor j<w[0]$, e $v[0]$ quando $j\geq w[0]$, isto é, considerando apenas o primeiro item, conseguimos obter o valor do primeiro item apenas quando a capacidade é maior ou igual ao peso dele. O caso geral nos diz que a solução de $T(i,j)$ é obtida da solução sem o $i$-ésimo item, $T(i-1,j)$, ou considerando o $i$-ésimo item. Se o $i$-ésimo item deve ser considerado, a solução ótima tem que partir de $T(i-1,j-w[i])$, a solução considerando os $i-1$ primeiros itens com capacidade máxima de $j-w[i]$, visto que queremos incluir um item de peso $w[i]$. Note que no segundo caso, $j$ deve ser maior ou igual ao peso do $i$-ésimo item, senão $T(i,j)$ deve considerar apenas $T(i-1,j)$.
Esta discussão nos leva para o seguinte código.
/**
* @brief Retorna o valor máximo considerando n itens cada um
* com um valor e peso sem exceder uma capacidade
*
* @param v valor dos itens
* @param w peso dos itens
* @param W capacidade máxima
* @return valor máximo dos itens sem exceder a capacidade W
*/
int boolean_knapsack(vector<int>& v, vector<int>& w,int W){
vector<vector<int>> dp(v.size(),vector<int>(W+1,0));
/***
* Caso base, olhando só o primeiro item, pegamos ele
* só quando a capacidade é maior ou igual ao peso dele
***/
for(int i=0;i<=W;i++){
if(i>=w[i]) dp[0][i] = v[i];
}
/***
* Caso geral, a solução para os i primeiros itens vem da solução
* dos i-1 primeiros itens com capacidade máxima de j
* (o i-ésimo item não é incluído), ou da solução
* dos i-1 priemiros itens com capacidade máxima j-w[i]
* mais o valor v[i] (o i-ésimo item é incluído)
***/
for(int i=1;i<v.size();i++){
for(int j=0;j<=W;j++){
dp[i][j] = dp[i-1][j];
if(j>=w[i])
dp[i][j] = max(dp[i][j],dp[i-1][j-w[i]]+v[i])
}
}
/***
* A solução ótima tem que estar na célula que considera todos os
* itens e a capacidade máxima
***/
return dp[v.size()-1][W];
}Como cada linha da matriz de programação dinâmica só depende da anterior, podemos realizar a computação utilizando apenas duas linhas, conforme código abaixo,
/**
* @brief Retorna o valor máximo considerando n itens cada um
* com um valor e peso sem exceder uma capacidade
*
* @param v valor dos itens
* @param w peso dos itens
* @param W capacidade máxima
* @return valor máximo dos itens sem exceder a capacidade W
*/
int boolean_knapsack(vector<int>& v, vector<int>& w,int W){
vector<vector<int>> dp(2,vector<int>(W+1,0));
/***
* Caso base, olhando só o primeiro item, pegamos ele
* só quando a capacidade é maior ou igual ao peso dele
***/
for(int i=0;i<=W;i++){
if(i>=w[i]) dp[0][i] = v[i];
}
/***
* Caso geral, a solução para os i primeiros itens vem da solução
* dos i-1 primeiros itens com capacidade máxima de j
* (o i-ésimo item não é incluído), ou da solução
* dos i-1 priemiros itens com capacidade máxima j-w[i]
* mais o valor v[i] (o i-ésimo item é incluído)
***/
int last = 0;
int cur = 1;
for(int i=1;i<v.size();i++){
for(int j=0;j<=W;j++){
dp[cur][j] = dp[last][j];
if(j>=w[i])
dp[cur][j] = max(dp[cur][j],dp[last][j-w[i]]+v[i])
}
swap(cur,last);
}
/***
* A solução ótima tem que estar na célula que considera todos os
* itens e a capacidade máxima
***/
return dp[last][W];
}Coin Change (Troco)
O problema do troco se resume a, dado um conjunto de valores de moeda $v= { v_0,v_1,\ldots,v_{n-1}} $, e uma quantia $W$, determinar o número mínimo de moedas que pague $W$. Neste problema, assume-se que existe uma quantidade infinita de moedas de cada valor.
A solução de programação dinâmica consiste em computar a seguinte relação de recorrência:
\[T(i,j) = \left\{ \begin{array}{l} 0,\quad j=0\\ j/v[0],\quad i=0\land j>0 \land j \mod v[0] = 0\\ \infty,\quad i=0 \land j>0 \land j \mod v[0] \neq 0\\ \min(a,b),\quad i>0 \quad \text{ em que} \\ \qquad a = T(i-1,j)\\ \qquad b = T(i,j-w[i]) + 1,\quad \text{ se $j\geq v[i]$}, \text{ ou $b=\infty$, caso contrário}.\\ \end{array} \right.\]A interpretação desta equação é $T(i,j)$ é o número mínimo de moedas para pagar o valor $j$ considerando apenas as moedas $v_0,\ldots,v_i$. O caso base, $j=0$ requer $0$ moedas, uma vez que o valor a ser pago é nulo. Considerando apenas a primeira moeda, quando $i=0$, só conseguimos pagar quando o valor $j$ é divisível por $v_0$; neste caso, utiliza-se $\frac{j}{v_0}$ moedas; caso contrário não há solução, simbolizado com o valor $\infty$. Para o caso geral, a solução pode: não utilizar a moeda $v_i$, neste caso a solução encontra-se em $T(i-1,j)$; utilizar a moeda $v_i$, neste caso a solução encontra-se em $T(i,j-v[i])$ e devemos adicionar mais uma moeda a solução, desde que $j\geq v[i]$. O segundo caso, diferentemente do Problema da Mochila Booleana, recupera a solução de $T(i,j-v[i])$ e não de $T(i-1,j-v[i])$, uma vez que admitimos repetição da $i$-ésima moeda.
Isto leva ao seguinte código.
/**
* @brief Retorna o número mínimo de moedas de um conjunto v
* a ser utilizadas para págar um troco W. Adimite-se
* que existem infinitdas moedas de cada valor de v.
*
* @param v valor das moedas
* @param W valor do troco.
* @return número mínimo de moedas para pagar W admitindo que
* podemos utilizar várias moedas de um mesmo valor.
*/
int boolean_knapsack(vector<int>& v,int W){
vector<vector<int>> dp(v.size(),vector<int>(W+1,0));
const int infinity = numeric_limits<int>::max() - 1;
/***
* Caso base: quando não há o que pagar, utiliza-se 0
* moedas
***/
dp[0][0] = 0;
/***
* Caso base, olhando só o primeiro item, pagamos só
* quando o valor a ser pago é divisível por v[0].
***/
for(int j=1;j<=W;j++){
if(j%v[0]==0) dp[0][j] = j/v[0];
else dp[0][j] = infinity;
}
/***
* Caso geral, a solução para as i primeiras moedas
* vem dos i-1 primeiros itens com troco j
* (a i-ésimo moeda não é incluída), ou da solução
* das i primeiras moedas com troco j-v[i] mais uma
* moeda (a i-ésima).
***/
for(int i=1;i<v.size();i++){
for(int j=0;j<=W;j++){
dp[i][j] = dp[i-1][j];
if(j>=v[i])
dp[i][j] = min(dp[i][j],dp[i-1][j-v[i]]+1)
}
}
/***
* A solução ótima tem que estar na célula que considera todas
* as moedas e o troco a ser pago.
***/
return dp[v.size()-1][W];
}O mesmo truque de economia de memória do problema da mochila 0-1 pode ser utilizada neste caso, uma vez que cada linha da matriz só depende da linha imediatamente anterior.